
redis:缓存穿透

redis:缓存穿透
小吴顶呱呱1.什么是缓存穿透
缓存穿透 :**缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。**可能是恶意用户伪造不存在的id发起请求,会导致缓存和数据库都无法查到,导致所有请求打到数据库上,数据库可能会因为扛不住压力而挂掉。
2.解决方案
常见的解决方案有两种:
-
缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成短期的不一致
-
布隆过滤
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能

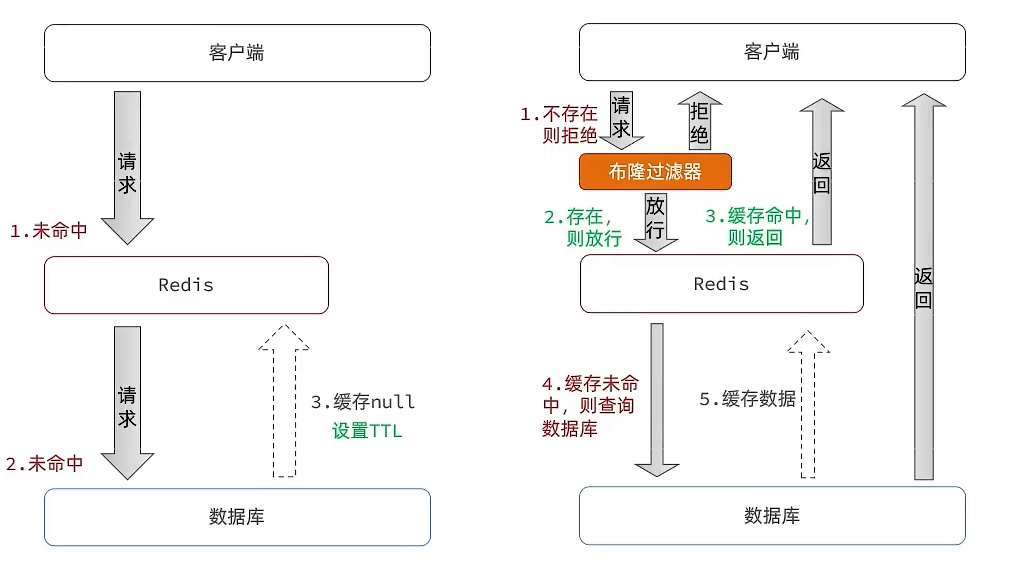
2.1缓存空对象
**缓存空对象思路:**当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了
1 | /** |
2.2 布隆过滤器
布隆过滤器底层是使用bit数组存储数据,该数组中的元素的默认值是0。而我们需要使用布隆过滤来解决缓存穿透问题,就需要将数据库中的数据缓存到布隆过滤器中(往往缓存key值)。在布隆过滤器第一次初始化的时候,会把数据库中所有的key(主键),经过一系列的hash算法(比如:三次hash算法)计算,每个key都会计算出多个位置,然后把这些位置上的元素值都设置为1.
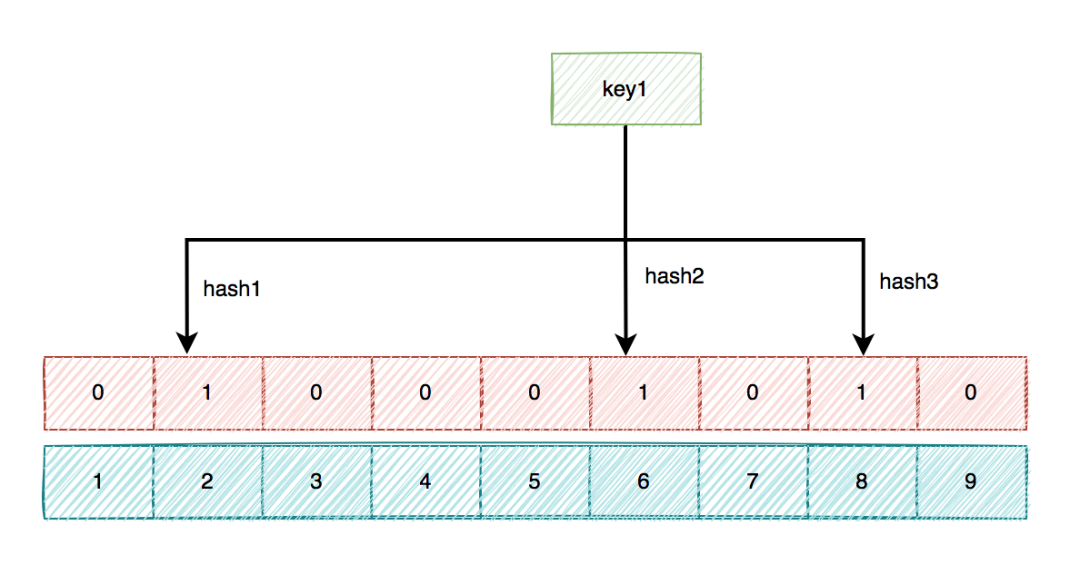
之后,有用户key请求过来的时候,再用相同的hash算法计算位置。
- 如果多个位置中的元素值都是1,则说明该key在数据库中已存在。这时允许继续往后面操作。
- 如果有1个以上的位置上的元素值是0,则说明该key在数据库中不存在。这时可以拒绝该请求,而直接返回。
假设布隆过滤器判断这个数据不存在,则直接返回
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突,因为存在hash冲突,所以说不同的key可能会计算出相同的位置。
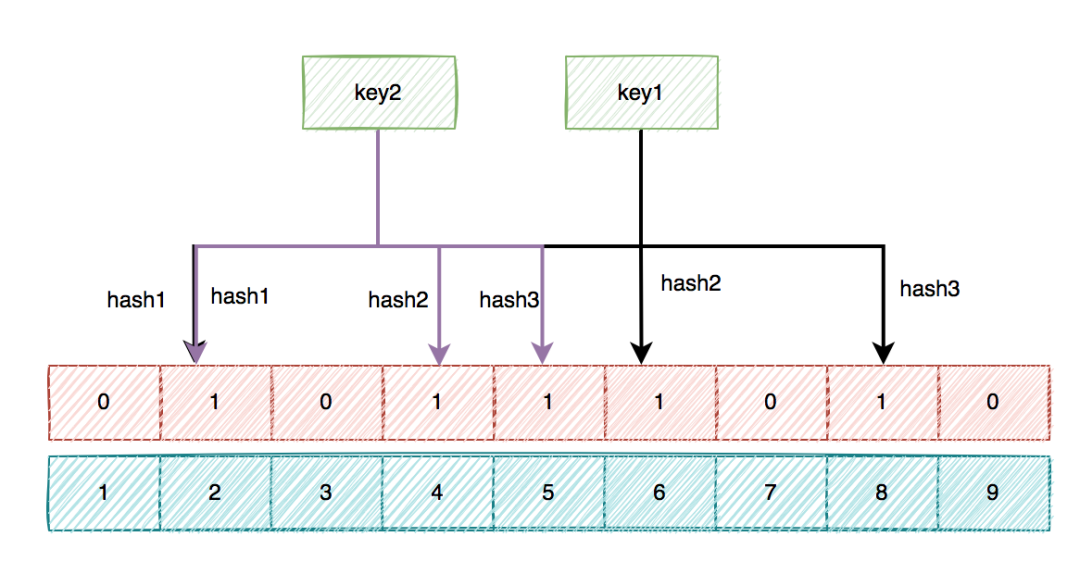
**布隆过滤器的特点:判断不存在,则该数据一定不存在,如果存在,则该数据可能存在;**如果想减少hash冲突,可以适当的增加hash函数。比如三次hash增加到五次hash。
另外使用布隆过滤器还需要考虑到当数据库中数据发生更新的时候,就会导致数据库中的数据和布隆过滤器中的数据不一致问题,这时候就需要进行数据同步,如果数据同步失败了(比如网络原因),可能就会发生数据库中存在的数据用户查找不到的问题!
布隆过滤器实现起来比较困难,实际应用中可以使用现成的布隆过滤器实现:
比如:Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现。在基于 Maven 的 Java 项目中要使用 Guava 提供的布隆过滤器,只需要引入以下坐标:
1 | <dependency> |
在导入 Guava 库后,我们可以通过 BloomFilter.create 方法来创建一个布隆过滤器







