
JUC(二):线程池

JUC(二):线程池
小吴顶呱呱1.线程池优点
前面我们说过,创建线程的一种方法就是使用线程池,那么使用线程池创建线程的好处是什么呢?
- 降低系统资源消耗,通过重用已存在的线程,降低线程的创建和销毁造成的消耗
- 提高系统的相应速度,当有任务到达时候,无需等待新线程的创建便可以立即执行
- 方便线程并发数的管控,线程不能无限制的创建,会消耗大量的系统资源,甚至会阻塞系统。线程池可以有效管控线程,统一分配,提高系统资源利用率
- 线程池提高了定时,定期以及可控线程数等功能,使用更加方便
2.四种线程池
Java 里面线程池的顶级接口是 Executor,但是严格意义上讲 Executor 并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是 ExecutorService。
自定义一个创建线程的通用线程工厂:
1 | public static class testThreadPoolFactory implements ThreadFactory { |
2.1 newCachedThreadPool
创建一个可缓存的无界线程池,如果线程池的长度超过处理需要,可灵活回收空线程,若无可用回收,则新建线程。当线程池中的线程空闲时间超过60s,则会自动回收该线程。线程池的大小上限为Integer.MAX_VALUE,可看作无限大。
1 | /** |
2.2 newFiexdThreadPool
创建一个指定大小的线程池,可控制线程的最大并发数量,超出的线程会在LinkBlockingQueue阻塞队列中等待
1 | /** |
2.3 newScheduledThreadPool
创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
1 |
|
2.4 newSingleThreadExecutor
Executors.newSingleThreadExecutor()返回一个线程池(这个线程池只有一个线程),这个线程池可以在线程死后(或发生异常时)重新启动一个线程来替代原来的线程继续执行下去!
1 | import java.util.concurrent.ExecutorService; |
3.ThreadPoolExecutor
Executors 的 4 个功能线程池就是基于ThreadPoolExecutor类实现的,虽然方便,但现在已经不建议使用了,而是建议直接通过使用 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
1 | public ThreadPoolExecutor(int corePoolSize, |
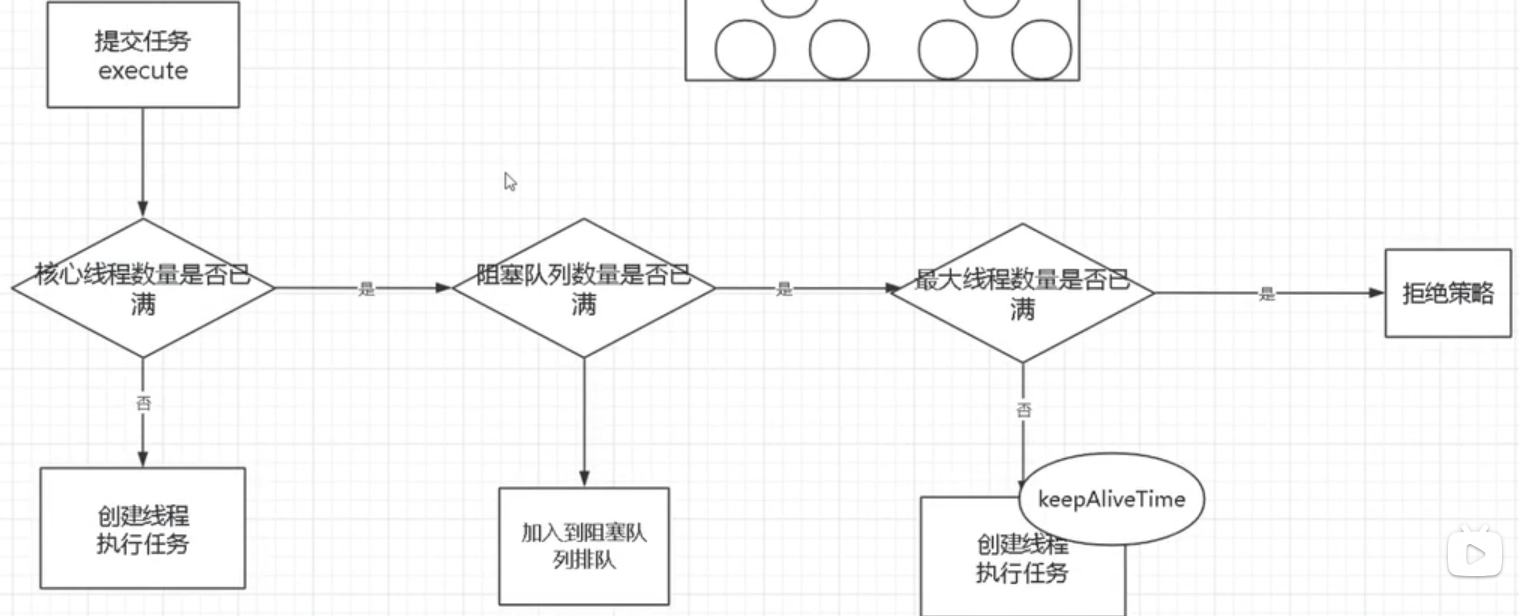
- corePoolSize(线程池基本大小,核心线程数):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时,才会根据是否存在空闲线程,来决定是否需要创建新的线程。
- maximumPoolSize(线程池最大大小):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
- keepAliveTime(非核心线程存活保持时间):默认情况下,当线程池的线程个数多于corePoolSize时,线程的空闲时间超过keepAliveTime则会终止。
- unit(存活时间的单位):时间单位
- workQueue(工作队列):用于传输和保存等待执行任务的阻塞队列。可以使用此队列与线程池进行交互:
如果运行的线程数少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。
如果运行的线程数等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。
如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。 - threadFactory(线程工厂):用于创建新线程。
- handler(拒绝策略):当线程池的线程数达到最大线程数时,需要执行拒绝策略。
- AbortPolicy(默认):丢弃任务并抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:由调用线程处理该任务
- DiscardPolicy:丢弃任务,但是不抛出异常。可以配合这种模式进行自定义的处理方式。
- DiscardOldestPolicy:丢弃队列最早的未处理任务,然后重新尝试执行任务
执行流程:
1 | // 创建线程池 |
4.BlockingQueue
当线程池中核心线程数满了之后,之后的任务就会加入阻塞队列,等待核心线程或者非核心线程处理。实现线程池中的阻塞队列主要有以下几种:
- ArrayBlockIingQueue:基于数组的有界阻塞队列,队列按照先进先出原则对任务进行排序。数组大小是固定的,一旦创建不能增加其容量。当阻塞队列满了之后,就不能再加入,进而再去创建线程,但不能超过线程池的最大线程数。
- LinkedBlockingQueue:基于链表的无界阻塞队列,FIFO。
- SynchronousQueue:同步阻塞队列,其中每个插入操作必须等待另一个线程的移除操作,同样任何一个移除操作都等待另一个线程的插入操作。因此此队列内部其 实没有任何一个元素,因此不能调用peek操作,因为只有移除元素时才有元素。所以实际上它不是一个真正的队列,因为SynchronousQueue没有容量。与其他BlockingQueue(阻塞队列)不同,SynchronousQueue是一个不存储元素的BlockingQueue。只是它维护一组线程,这些线程在等待着把元素加入或移出队列
- PriorityBlockingQueue:基于优先级的无界阻塞队列。对队列中的元素进行排序,如果未指定比较器,插入队列的元素必须实现Comparable接口,内部是基于数组实现的最小二叉堆算法,队列的长度是可扩展的(类似ArrayList),上限为Integer.MAX_VALUE - 8。
5 submit和execute
在线程池的使用中,我们一般用ThreadPoolExecutor来创建线程池,创建好线程池后会将任务提交给线程池来执行。在提交任务的时候,JDK为我们提供了两种不同的提交方式,分别是submit()和excute():
execut()是在线程池的顶级接口Executor中定义的,而且只有这一个接口,可见这个方法的重要性。
1 | public interface Executor { |
在ThreadPoolExecutor类中有它的具体实现。
submit()是在ExecutorService接口中定义的,并定义了三种重载方式:
1 |
|
在AbstractExecutorService类中有它们的具体实现,而ThreadPoolExecutor继承了AbstractExecutorService类,所以也有得到submit方法
-
由此可以看出,他们俩虽然都是提交任务给线程池,但是由于参数不同,Executor只能接收实现
Runnable接口类型的任务,而submit则既可以接收Runnable类型的任务,也可以接收Callable类型的任务。 -
有无返回值:execute()的返回值是void,线程提交后不能得到线程的返回值。submit()的返回值是Future,通过Future的get()方法可以获取到线程执行的返回值,get()方法是同步的,执行get()方法时,如果线程还没执行完,会同步等待,直到线程执行完成。
⚠️虽然submit()方法可以提交Runnable类型的参数,但执行Future方法的get()时,线程执行完会返回null,不会有实际的返回值,这是因为Runnable本来就没有返回值
-
异常处理:execute在执行任务时,如果遇到异常会直接抛出,而submit不会直接抛出,只有在使用Future的get方法获取返回值时,才会抛出异常;所以当用submit()提交线程时,
run()或call()方法应该显示catch异常。
6.示例
下面是一个使用ThreadPoolExecutor实现的线程池完整实例代码:
1 | import java.util.concurrent.ArrayBlockingQueue; |
在这个例子中,我们创建了一个ThreadPoolExecutor实例,设置了2个核心线程和4个最大线程,队列容量为10。然后提交了10个任务给线程池执行。每个任务都是一个实现了Runnable接口的Task类的实例。在Task的run方法中,我们打印了任务的ID和执行线程的名称,并且让任务线程休眠1秒模拟任务执行。最后,我们关闭了线程池。








